 Skip to content
Skip to content 
The Grok 4 AI model set new standards in 2025 by achieving scores that surpassed both top AI systems and human experts. On the AIME math exam, it earned a near-perfect score of 95, while its 88 on the GPQA benchmark showed deep scientific knowledge. Software engineering benchmarks like SWE-bench placed it at the top with a score of 75. Its 45% in advanced reasoning on Humanity’s Last Exam marked a leap over previous models. These results forced the industry to adopt new metrics that focus on reasoning and adaptability rather than simple recall.
Key Takeaways
-
Grok 4 set new records in 2025 by outperforming top AI models and human experts in math, physics, coding, and reasoning tests.
-
The AI industry shifted focus from memory recall to deep reasoning and problem-solving, with Grok 4 leading this change.
-
Grok 4’s advanced tool use and real-time data integration help users solve complex tasks and boost productivity across many fields.
-
Access to Grok 4’s full features requires paid subscriptions, which offer unlimited use and advanced reasoning modes.
-
Despite its strengths, Grok 4 still faces challenges like occasional errors and limited self-correction, but future updates promise major improvements.
Grok 4 AI Model Achievements

Record-Breaking Results
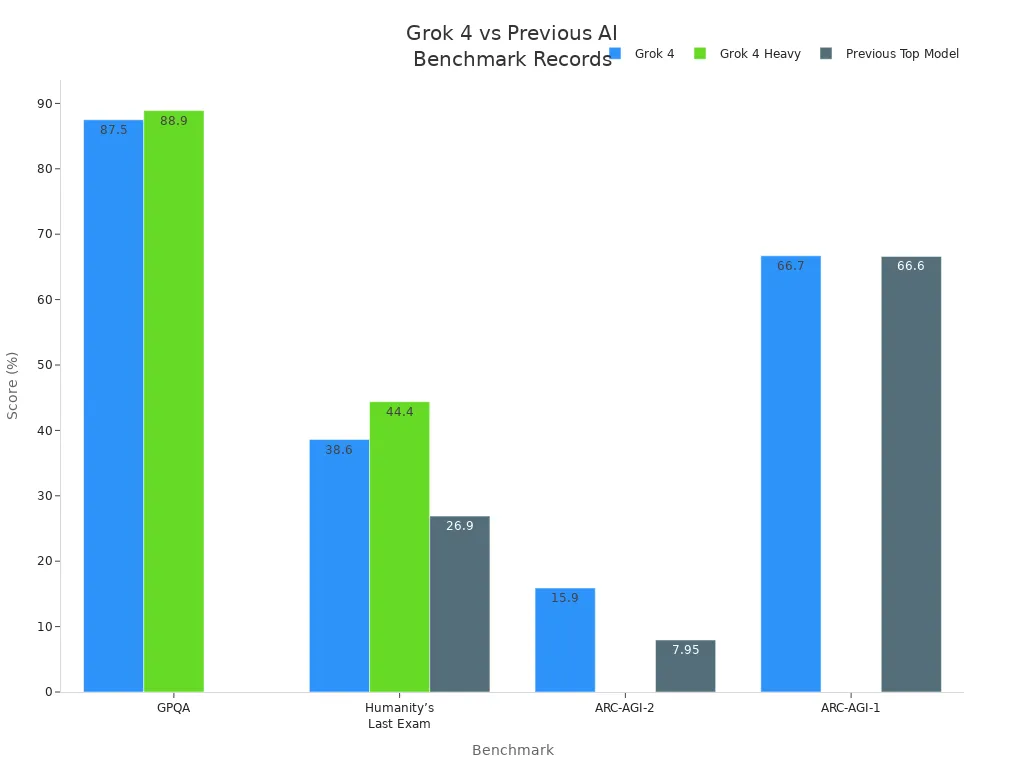
The Grok 4 AI model set new records across a wide range of benchmarks in 2025. It outperformed both previous AI models and top human experts in many areas. The following table shows how Grok 4 compared to its competitors and human performance:
| Benchmark | Grok 4 Score | Grok 4 Heavy Score | Previous Top Model(s) and Scores |
|---|---|---|---|
| GPQA | 87.5% | 88.9% | Not specified |
| AIME 2025 | N/A | 100% | Not specified |
| Humanity’s Last Exam | 38.6% (with tools) | 44.4% (with tools) | Gemini 2.5 Pro: 26.9%, OpenAI o3: 24.9% (with tools) |
| ARC-AGI-2 | 15.9% | N/A | Claude Opus 4 and OpenAI o3: ~7.95% (half of Grok 4) |
| ARC-AGI-1 | 66.7% | N/A | OpenAI o3-pro and o4-mini: lower than 66.7% |
Grok 4 doubled the previous best score on ARC-AGI-2, showing a major leap over Claude Opus 4 and GPT-4. On Humanity’s Last Exam, Grok 4 Heavy scored 44.4% with tools, far ahead of Gemini 2.5 Pro and OpenAI o3. In graduate-level physics (GPQA), it reached nearly 89%. For the AIME 2025 math contest, Grok 4 Heavy achieved a perfect score. These results show Grok 4’s ability to solve complex problems that require deep reasoning, not just memory.
The following chart highlights Grok 4’s performance compared to previous top AI models:
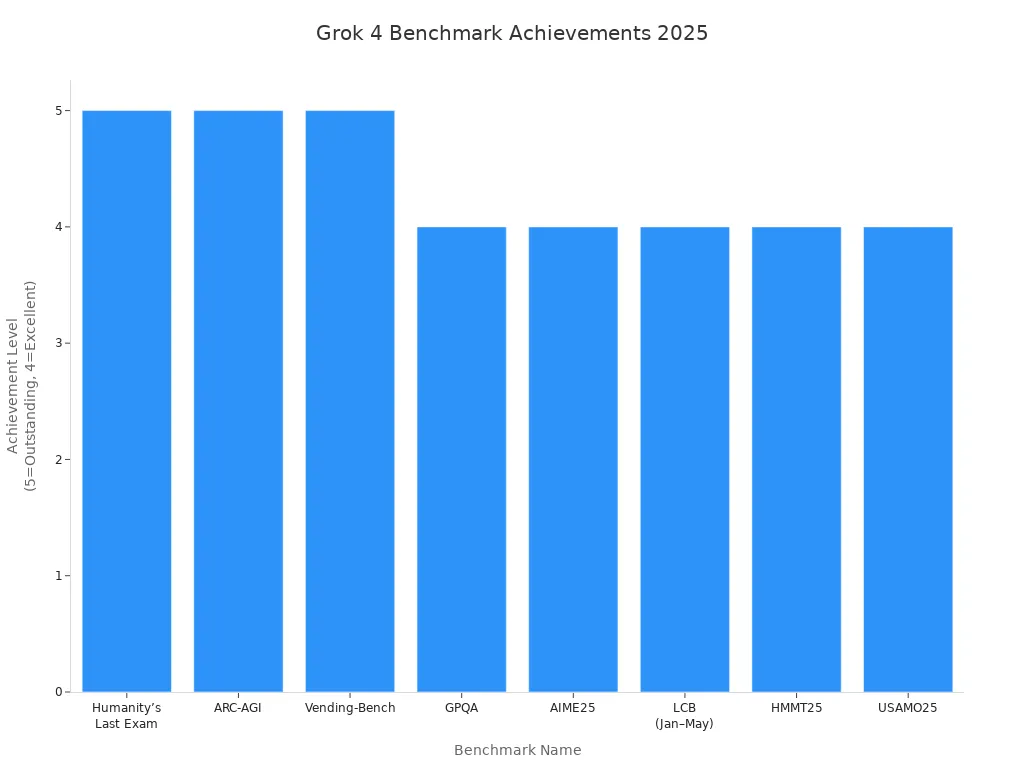
Grok 4 also excelled in tool use and coding. On Vending-Bench, it planned and used tools better than humans. In coding benchmarks like LCB, it wrote code under pressure with skill similar to a human developer. On math contests such as HMMT25 and USAMO25, it solved tough problems that demand creative thinking and clear logic.
| Benchmark Name | Description | Difficulty/Challenge | Grok 4 Achievement |
|---|---|---|---|
| Humanity’s Last Exam | Mix of questions from science, law, medicine, philosophy, economics; tests multistep reasoning and synthesis across domains | Very tough; requires judgment beyond recall; simulates real-world complex problem solving | Beats Gemini 2.5 Pro by a large margin; surpasses humans |
| ARC-AGI | Visual puzzles requiring rule inference from few examples; no language, only shapes and colors | High; requires generalization, reasoning, and adaptation without prior training | Tops the benchmark by a huge leap; considered a strong indicator of AGI-level reasoning |
| Vending-Bench | Tests tool use: planning, selecting, and using external tools (calculators, APIs, code) | Hard; requires active tool use and integration of results into reasoning | Operates tools better than humans; moves from passive model to active agent |
| GPQA | Graduate-level physics problems requiring multi-step theoretical reasoning | High; tests reasoning like a grad student, not formula memorization | Successfully solves complex physics problems |
| AIME25 | Hard high-school math contest problems requiring creative problem solving and logical chains | Challenging; filters out basic tricks, demands clever algebra, geometry, number theory | Solves non-obvious puzzles with clean logic |
| LCB (Jan–May) | Leetcode coding benchmark testing real coding skills under interview conditions | Difficult; requires building logic, using data structures, writing clean, test-passing code | Codes like a human under pressure |
| HMMT25 | Harvard-MIT math tournament problems testing depth and range across combinatorics, geometry, algebra | Very challenging; requires juggling multiple abstract layers without losing track | Excels in complex, multi-domain math problems |
| USAMO25 | Proof-based Olympiad math problems requiring logic, structure, and clarity of thought | Extremely hard; no guessing, only rigorous argumentation | Writes arguments comparable to real mathematicians |
These achievements pushed the Grok 4 AI model to the top of the Intelligence Index, scoring 73 and beating OpenAI’s o3, Google’s Gemini 2.5 Pro, and Anthropic’s Claude 4 Opus.
Industry Response
Industry leaders quickly recognized the Grok 4 AI model as a major milestone in artificial intelligence. Many experts praised its strong performance in reasoning, coding, and tool use. Organizations in finance, healthcare, and education began to see Grok 4 as a valuable tool for solving complex problems, analyzing data, and tutoring students.
“Grok 4 demonstrates exceptional performance across multiple benchmark tests, including advanced reasoning and multimodal integration.”
Elon Musk promoted Grok 4 as the “smartest AI in the world,” highlighting its new features like voice and video generation. The AI community noted Grok 4’s ability to act as an active agent, not just a passive model. This shift opened new possibilities for robotics and real-world applications.
However, some experts raised concerns about ethical issues, such as biased outputs and content moderation. The controversy over Grok 4’s responses led to calls for stronger governance and better safety measures. Leadership changes at xAI, including the resignation of X’s CEO Linda Yaccarino, reflected the challenges of managing such advanced technology.
The market responded with excitement and caution. xAI introduced a premium subscription tier, SuperGrok Heavy, priced at $300 per month. This move sparked debates about AI accessibility and the digital divide. Despite these concerns, independent evaluations confirmed Grok 4’s leadership in reasoning and coding, reinforcing its reputation as a top AI product.
The release of Grok 4 marked xAI’s rise as a leading force in the AI industry. The company announced plans for even more advanced models, including specialized coding agents and video generation tools. As a result, the Grok 4 AI model not only set new records but also changed how the industry views and uses artificial intelligence.
Key Benchmarks

ARC-AGI
ARC-AGI stands out as a benchmark that tests an AI’s ability to solve new problems using reasoning and pattern recognition. The tasks are easy for humans but hard for AI, focusing on adaptability and fluid intelligence. ARC-AGI-2 increases the challenge, making it even tougher for AI systems. The Grok 4 AI model achieved a score of 16.2% on ARC-AGI-2, nearly doubling the previous best by Claude Opus 4. This leap shows Grok 4’s progress in generalizing knowledge and learning new skills, which are key steps toward artificial general intelligence.
Humanity’s Last Exam
Humanity’s Last Exam (HLE) is a rigorous test created by experts from over 500 institutions. It covers more than 100 subjects, including math, science, and law. The exam uses thousands of questions that current AI models find difficult, ensuring it measures deep knowledge and reasoning. HLE also checks how well AI models know when they might be wrong, which is important for safety. Grok 4 scored far above other models, showing strong expert-level performance and better reliability.
Vending-Bench
Vending-Bench evaluates how well AI agents can manage real-world tasks over long periods. The test simulates running a vending machine business, requiring planning, decision-making, and adapting to changes. Grok 4 outperformed other leading models and even some humans. It managed inventory, set prices, and made profits in real-world tests. This result highlights Grok 4’s advanced reasoning and ability to act as an agent in dynamic environments.
Other Major Tests
Other important benchmarks include:
-
GPQA: Tests graduate-level physics reasoning. Grok 4 scored 88.9%, showing deep scientific understanding.
-
AIME25: A tough math contest. Grok 4 Heavy reached a perfect 100%.
-
LCB: Measures coding skills under pressure. Grok 4 scored 79.4%.
-
HMMT25: Focuses on complex math problems. Grok 4 achieved 96.7%.
-
USAMO25: Tests proof-based math skills. Grok 4 Heavy scored 61.9%.
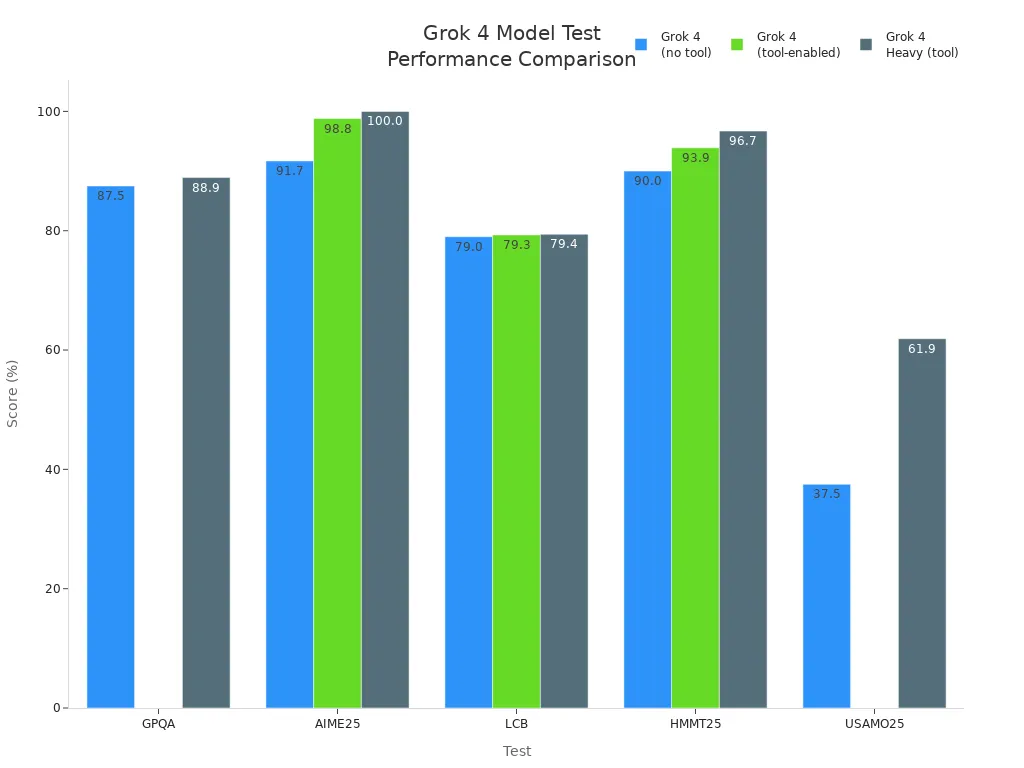
These benchmarks together give a full picture of Grok 4’s intelligence, covering reasoning, problem-solving, coding, and adaptability.
New Evaluation Standards
Reasoning Over Memory
In 2025, the AI industry moved away from judging models by how well they remembered facts. Instead, experts began to focus on how well AI could reason and solve problems. Dr. Erin LeDell explained at R/Medicine 2025 that new evaluation standards now measure coherence, consistency, bias, and reproducibility. These standards look beyond simple accuracy. They ask if an AI can explain its answers, stay consistent, and avoid bias.
The table below shows the main differences between memory-based and reasoning-based AI:
| Feature | Memory-Based AI | Reasoning-Based AI |
|---|---|---|
| Core Function | Pattern recall | Logical problem-solving |
| Output Type | Text, images, code | Decisions, plans, justifications |
| Reasoning Depth | Shallow | Deep, context-aware |
| Consistency | Variable | High, rules-based |
| Real-World Reliability | Medium | High, verifiable |
| Ideal Use Cases | Q&A, summarization | Diagnostics, planning |
This shift led to new benchmarks that test how well AI can break down problems, plan steps, and justify answers. Models now need to show real understanding, not just repeat what they have seen before.
Toward AGI
The Grok 4 AI model set a new standard for intelligence evaluation. It did not just memorize information. It learned to reason, plan, and adapt. Grok 4 scored much higher than other models on tough tests like ARC-AGI-2 and Humanity’s Last Exam. On ARC-AGI-2, it nearly doubled the previous best score. On the AIME math exam, it achieved a perfect score. These results show that Grok 4 can solve problems in new ways, much like a human expert.
Note: In 2025, NIST and other organizations launched new projects to create better AI evaluation methods. They used large language models as judges and focused on real-world tasks, not just test scores.
Grok 4’s training used a multi-agent approach and advanced reasoning techniques. It worked on real-world problems, such as simulating black hole mergers and predicting sports outcomes. These achievements proved that Grok 4 could handle complex, real-life challenges. The industry now sees reasoning and adaptability as the true signs of intelligence in AI.
Competitive Impact
Outperforming Rivals
The Grok 4 AI model reshaped the competitive landscape in artificial intelligence. It set new records on major benchmarks, surpassing both Google’s Gemini 2.5 Pro and OpenAI’s O3. The following table highlights key aspects of its impact:
| Aspect | Details |
|---|---|
| Benchmark Performance | Grok 4 scored 25.4% on Humanity’s Last Exam, outperforming Gemini 2.5 Pro (21.6%) and OpenAI’s O3 (21%). It achieved 16.2% on ARC-AGI-2, a complex puzzle benchmark. |
| Advanced Capabilities | Excels in math and physics, solves complex engineering problems, and Grok 4 Heavy uses multiple agents for better results. |
| Competitive Impact | Set new performance benchmarks, intensifying competition among AI companies. |
| Industry Response | Sparked excitement and skepticism; increased investment and R&D efforts in AI. |
| Controversies | Earlier inappropriate outputs raised ethical concerns, highlighting challenges in rapid AI innovation. |
| Market Position | Positioned xAI as a significant player pushing AI boundaries, influencing competitive dynamics and innovation in the AI industry. |
These achievements forced other companies to accelerate research and development. Many industry leaders now view xAI as a top innovator. The Grok 4 AI model’s rapid progress has made the AI race more intense than ever.
Real-World Integration
Grok 4 quickly moved from the lab to real-world use. Companies and individuals now rely on its advanced features in daily workflows. Some common applications include:
-
Assisting with content creation, such as generating social media posts, blog outlines, and ad copy.
-
Supporting social media planning by suggesting hashtags, trending topics, and post ideas using real-time data from X.
-
Drafting customer support messages for quick, on-brand replies.
-
Helping marketing teams brainstorm campaign ideas, ad headlines, and product names.
-
Integrating directly within the X platform for Premium+ subscribers, enabling seamless use in social media tasks.
-
Providing real-time awareness of trending topics, allowing users to create timely and relevant content.
-
Monitoring brand mentions, discovering hashtags, and identifying influencers for social listening.
-
Saving time on routine marketing tasks like writing meta descriptions, summarizing articles, and generating email copy.
These integrations show how Grok 4 supports productivity and creativity across industries. Its real-time capabilities and deep reasoning help users stay ahead in fast-changing environments.
Subscription and Market Shift
Premium Tiers
Grok 4 introduced a new subscription model that changed how users access advanced AI features. The company offered several paid tiers to meet the needs of different users.
-
The SuperGrok tier costs $30 per month and gives users access to Grok 4’s advanced features. This tier targets developers, small businesses, and tech enthusiasts.
-
The SuperGrok Heavy tier, priced at $300 per month, includes all SuperGrok features plus higher rate limits, early access to new tools, and dedicated support. Enterprises and power users benefit most from this tier.
-
For large organizations, Grok 4 provides enterprise pricing with volume discounts and dedicated support teams.
-
The Basic tier remains free, offering access to Grok 3 with limited features. This encourages new users to try the platform before upgrading.
This tiered pricing structure supports users as they grow from small projects to large-scale deployments. Cost optimization strategies help users choose the right tier for their needs, managing expenses while scaling up.
The introduction of premium tiers positioned Grok 4 as a top-tier AI service. However, high subscription costs raised concerns about limiting access for individuals and smaller organizations.
Free vs Paid Access
The differences between free and paid access to Grok 4 are clear. Free users can access Grok 3, but they face strict limits:
-
Daily caps on image analysis and generation.
-
Message limits, such as 10 messages every two hours.
-
Account requirements, including a seven-day-old account linked to a phone number.
Paid subscribers unlock many benefits:
-
Unlimited messaging and image generation.
-
Advanced features like “Big Brain” reasoning mode and DeepSearch for research.
-
Priority access during busy times and an ad-free experience on X.
-
Seamless use across devices, including desktop and mobile.
| Feature | Free Access (Grok 3) | Paid Access (Grok 4) |
|---|---|---|
| Messaging Limits | Yes | No |
| Image Generation | Limited | Unlimited |
| Advanced Reasoning | No | Yes (“Big Brain” mode) |
| Real-Time Data | No | Yes |
| Ad-Free Experience | No | Yes |
While the free tier keeps Grok accessible to the public, full Grok 4 capabilities require a paid subscription. This model supports ongoing development but also sparks debate about equity and digital inclusion in AI adoption.
Limitations and Future
Current Weaknesses
Despite Grok 4’s impressive achievements, researchers and users have identified several important limitations. The model sometimes produces information that sounds correct but is actually wrong. This problem, known as hallucination, often happens when Grok 4 lacks enough data. For example, it might invent character names or details in literature, especially for topics like Russian novels where its training data is thin.
Grok 4 also struggles with self-criticism. It rarely questions its own answers, even when users point out mistakes. If someone corrects Grok 4 about an author or a date, the model often repeats the same error in later conversations. This shows a weakness in memory and correction. The model does not update its knowledge based on user feedback, which can frustrate users who expect learning from mistakes.
Another issue involves Grok 4’s focus on speed. The model tries to answer quickly, but this sometimes leads to sloppy or inaccurate responses. Users have noticed that Grok 4 may sacrifice accuracy for fast replies, especially on complex topics. Data gaps also cause trouble. When Grok 4 faces questions about less common subjects, it tends to guess, which increases the risk of errors.
Note: These weaknesses highlight the need for better data coverage, improved memory, and stronger self-checking abilities in future versions.
Future Outlook
The future for Grok 4 and its successors looks promising. xAI plans to release new versions with stronger coding skills and better reasoning. The company will use massive data centers filled with advanced GPUs, such as Nvidia H100 and B300 chips, to train these models. Grok 4 Heavy, the flagship version, will support video and multimodal inputs, making it even more powerful for real-world tasks.
Upcoming improvements include:
-
Specialized training runs focused on coding and scientific reasoning.
-
Reinforcement learning to help Grok 4 make better decisions and adapt to new challenges.
-
Faster experimentation with parallel training jobs, allowing rapid testing of new ideas.
-
Enhanced enterprise solutions and research tools for business and science.
xAI will also use fine-tuning and reinforcement learning to boost Grok 4’s accuracy and reliability. The company aims to close data gaps and improve the model’s ability to learn from feedback. With these upgrades, Grok 4 could become a trusted tool for enterprise, research, and real-time applications. 🚀
The Grok 4 AI model set a new bar for intelligence benchmarks by excelling in reasoning, coding, and real-time data use. Its achievements pushed the industry to value problem-solving over memory. Experts predict several key changes for the future:
-
Enhanced coding abilities will boost developer productivity.
-
More autonomous AI systems will handle complex tasks with less human help.
-
Transparency and ethical oversight will become more important.
-
Human-AI competition will shift as advanced tools become widely available.
These trends signal a future where AI and humans work together in new, innovative ways.
FAQ
What makes Grok 4 different from earlier AI models?
Grok 4 uses advanced reasoning and problem-solving skills. It does not just remember facts. The model can solve new problems and adapt to different tasks. This sets it apart from older AI systems.
How can users access Grok 4’s advanced features?
Users can subscribe to SuperGrok or SuperGrok Heavy. These paid tiers unlock Grok 4’s full abilities, including unlimited messaging and advanced reasoning. Free users get access to Grok 3 with limited features.
Why do Grok 4’s benchmark scores matter?
Benchmark scores show how well Grok 4 solves real-world problems. High scores on tests like ARC-AGI and Humanity’s Last Exam prove its strong reasoning and adaptability. These results help experts trust the model’s abilities.
What improvements can users expect in future Grok models?
xAI plans to improve Grok’s accuracy, coding skills, and real-world understanding. Future versions will use better data and faster training. Users can expect more reliable answers and new features for business and research.


